Index
Lecture7
Note for Coursera Machine Learning made by Andrew Ng.
Regularization
The problem of overfitting
Overfitting examle (Intro)
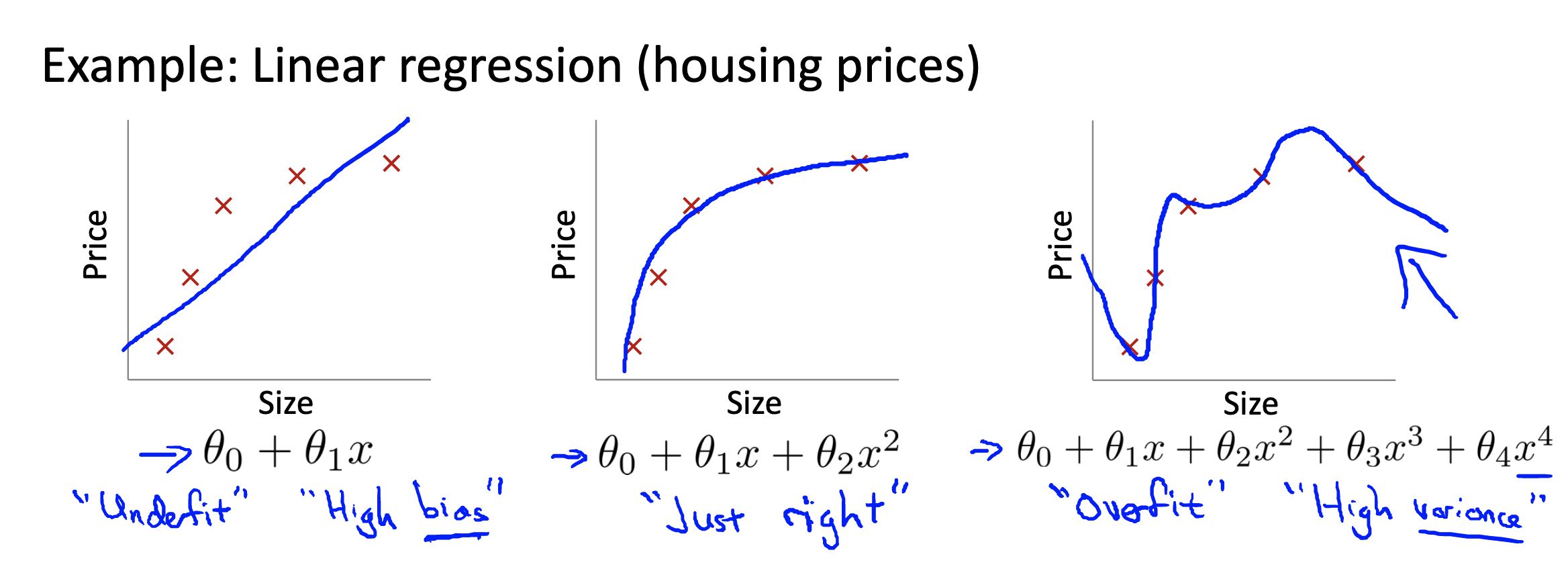
- Overfitting: If we have too many features, the learned hypothesis may fit the training set very well (
), but fail to generalize to new examples (predict prices on new examples).
Example of overfitting in classification problem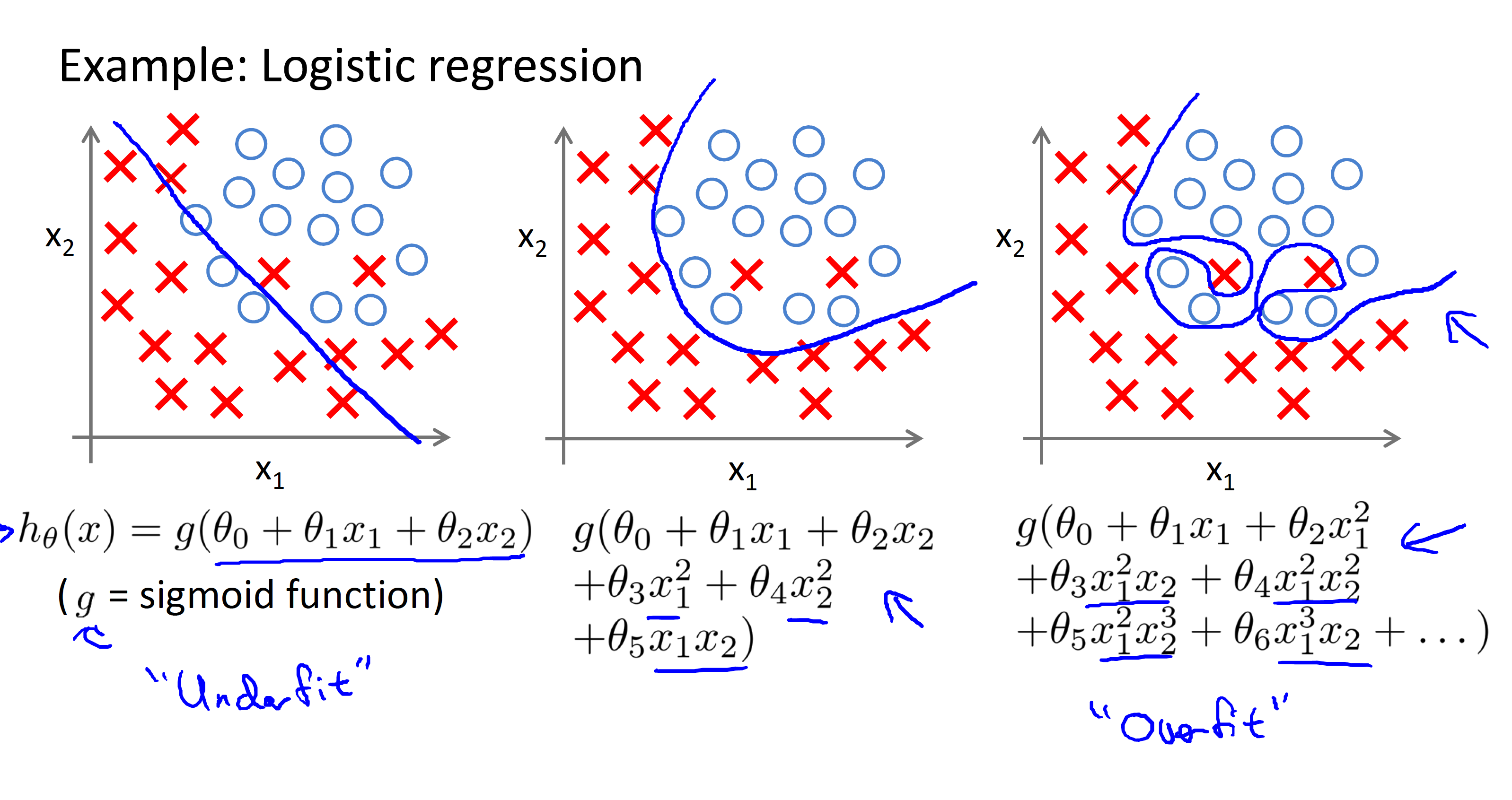
Addressing overfitting
For example we have an overfitting example with 100 features (
- In order to address it, we have following options:
- Reduce number of features.
- Manually select which features to keep.
- Model selection algorithm (later in course).
- Regularization
- Keep all the features, but reduce magnitude/values of parameters
- Works well when we have a lot of features, each of which contributes a bit to predicting
.
- Keep all the features, but reduce magnitude/values of parameters
- Reduce number of features.
Link to coursera section
https://www.coursera.org/learn/machine-learning/supplement/VTe37/the-problem-of-overfitting
Cost fumction
Intuition
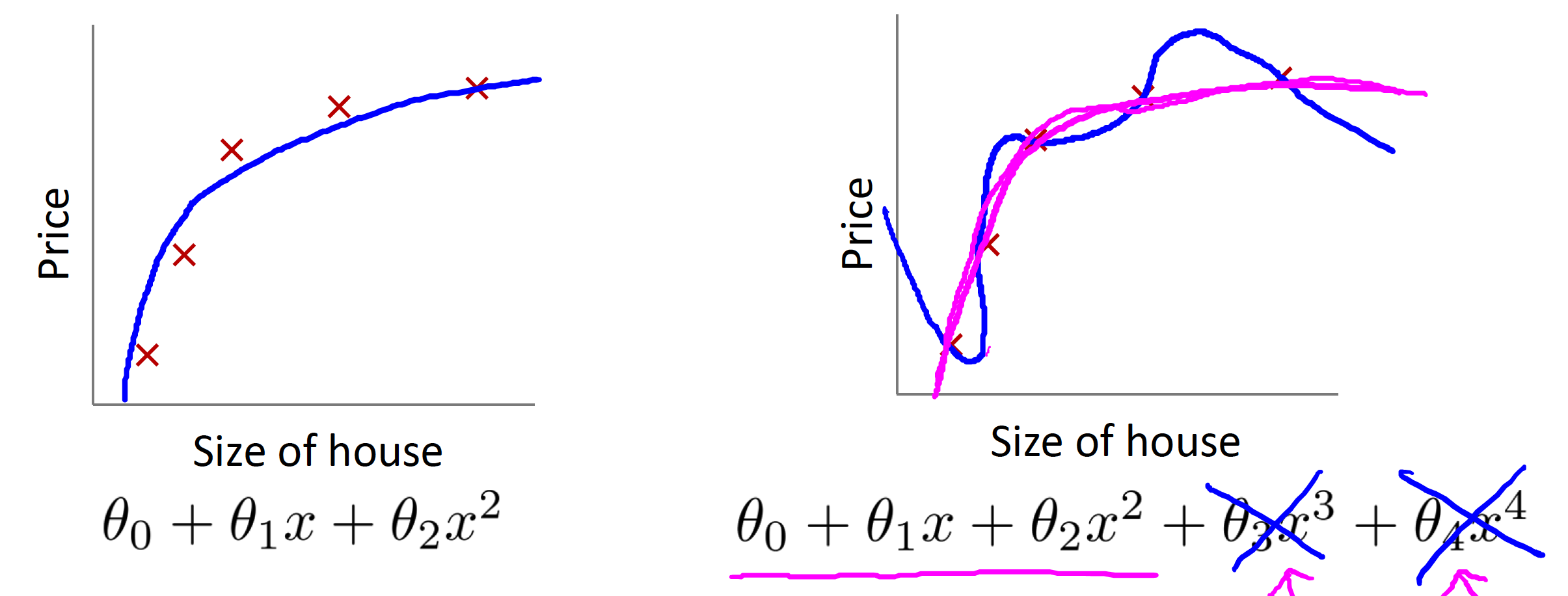
- Suppose we penalize and make
, really small. - Where
and *
Then we can flattern the graph by doing above process. (see pink part in the figure)
Regularization
- Small values for parameters
- “Simpler” hypothesis
- Less prone to overfitting
- Housing:
- Features:
- Parameters:
(example in intuition part)
- Features:
Below is the cost function with regularization term
- The
, or lambda, is the regularization parameter. It determines how much the costs of our theta parameters are inflated. used here is to make sure we are dealing with magnitude/values of parameters
What if
- Will cause underfit. (see reason below)
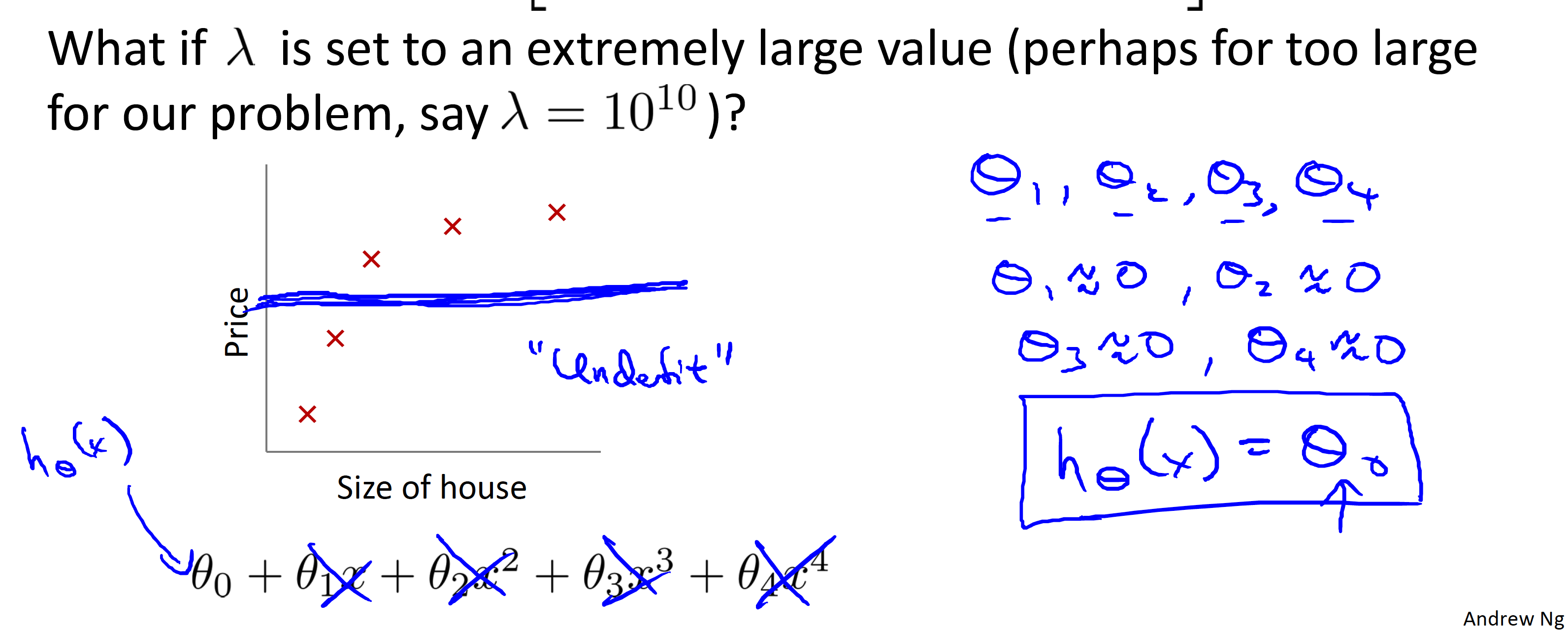
Link to coursera section
https://www.coursera.org/learn/machine-learning/supplement/1tJlY/cost-function
Regularized linear regression
Gradient descent

Note!
The regularization term sum from
For more info:
Bias term info:
Normal equation
Normal equation Non-invertibility
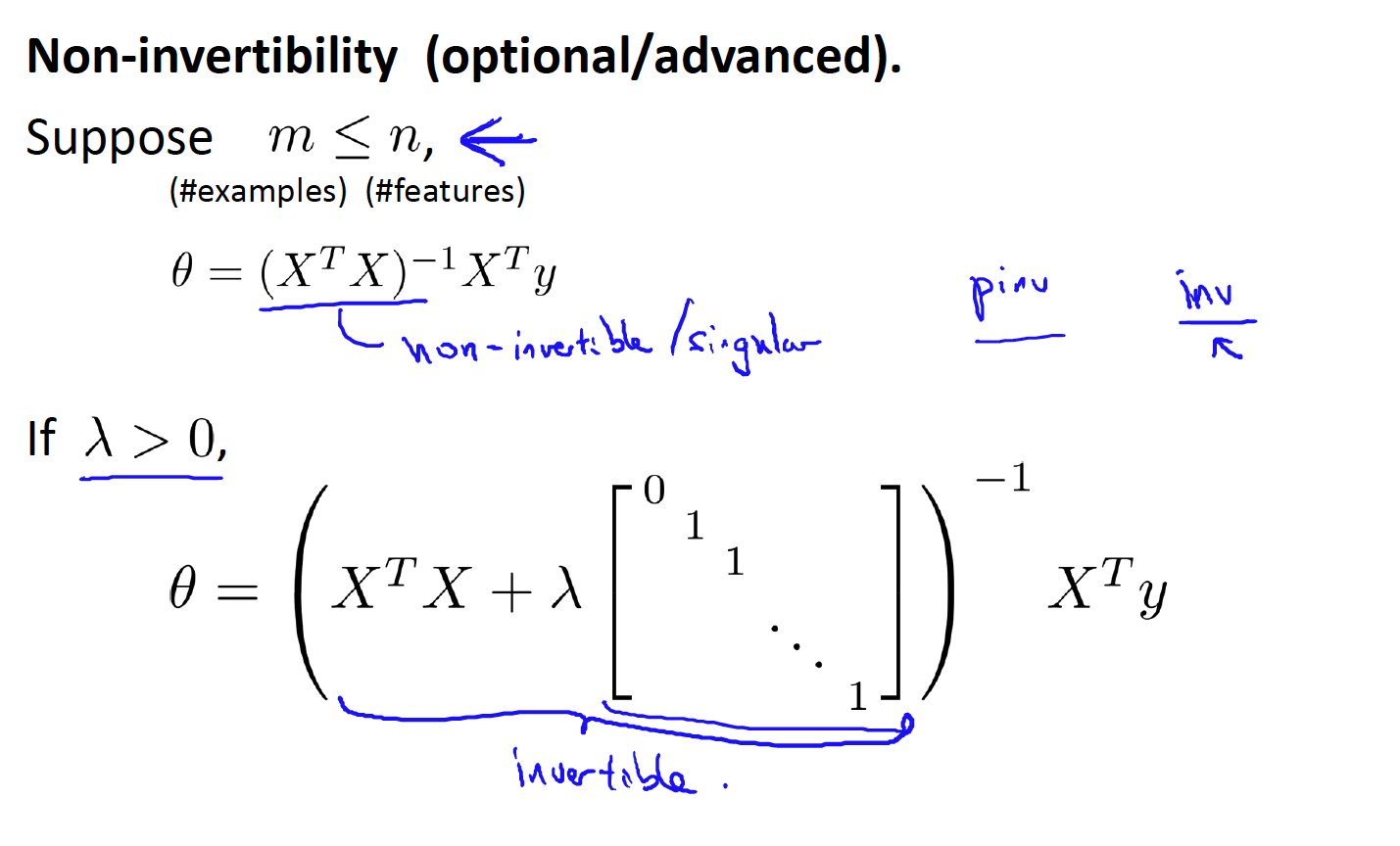
- proof and more details, see below:
https://web.mit.edu/zoya/www/linearRegression.pdf
Link to coursera section
https://www.coursera.org/learn/machine-learning/supplement/pKAsc/regularized-linear-regression
Regularized logistic regression
- The second sum,
means to explicitly exclude the bias term, . I.e. the vector is indexed from 0 to n (holding n+1 values, through ), and this sum explicitly skips , by running from 1 to n, skipping 0.
Gradient descent
Advanced optimization

Link to coursera section
https://www.coursera.org/learn/machine-learning/supplement/v51eg/regularized-logistic-regression

Sukoshi
贵在坚持
23
4
23